The world runs on data. A hallmark of successful businesses is their ability to use quality facts and figures to their advantage. Unfortunately, data rarely arrives ready to use. Instead, businesses often inherit a mess of information from numerous sources that is inadequate for analysis or effective use.
Enter data cleaning. This process takes data and turns it into reliable, quality information. Most importantly, this data is now usable for future business needs. This guide will walk you through data cleaning basics, how to do it and why every business that wants to use data must first clean it.
What is data cleaning and why is it important?
Data cleaning, also known as data cleansing or data scrubbing, is all about making sure the data on hand is of good quality. This process, which is the first step of any further data analytics or visualization effort, ensures that all future work is reliable. Without quality, clean data, any further work is ultimately undependable.
“Data cleaning is about making sure your data reflects the real world as accurately as possible,” said Dan Ginder, a senior data scientist and engineer at an emergency management consulting firm. “It’s about fixing errors, filling in missing information and getting rid of anything that doesn’t belong. Think of data cleaning like building the foundation of a house.”
When considering data cleaning, remember the adage “garbage in, garbage out.” Any work with data requires quality data to output anything of value. Data cleaning, then, is of paramount importance to ensure that future work with data is worth anything and does not end up just being fancy-looking garbage.
“Raw data is almost always dirty,” explained Victoria Papalian, chief operating officer at Udacity. “You might have duplicate records, timestamps in different formats, incomplete entries or values that don’t make sense. Data cleaning ensures you’re making decisions based on accurate information.”
In fact, data cleaning is so important that it is estimated that upwards of 80 percent of the entire data analysis process is spent on cleaning and preparing the data, according to the book “Exploratory Data Mining and Data Cleaning” by Tamraparni Dasu and Theodore Johnson. Data cleaning is not just the first step of an analysis — cleaning should be done over the course of the entire project as further data is collected, models are refined and potentially new problems crop up.
Another reason data cleaning takes up so much time is due to how broad cleaning is. This process includes everything from outlier checking to missing value imputation to spell checking. Additionally, tidying up data to ensure it is in a usable state for current analysis, while also being in a format to allow for additional data to be added, if necessary, is also all part of the cleaning process.
Data cleaning is increasingly important as a greater share of business functions rely on big data analysis. For example, as businesses increasingly implement artificial intelligence (AI) and machine learning systems into their workflows, being sure that the tools have access to reliable, clean data is paramount to ensuring these systems work properly.
According to
Forrester’s Data Culture and Literacy Survey, over 25 percent of data and analytics employees believe their companies lost more than $5 million annually due to poor data. Additionally, 7 percent of surveyed employees reported that poor data quality led to losses of $25 million or more annually.
What are the key steps in the data cleaning process?
As data cleaning is so broad, and so unique to each individual data set, there is not always a clear order of steps to take to end up with clean data. Even so, there is still a logical flow to the cleaning process, Papalian noted.
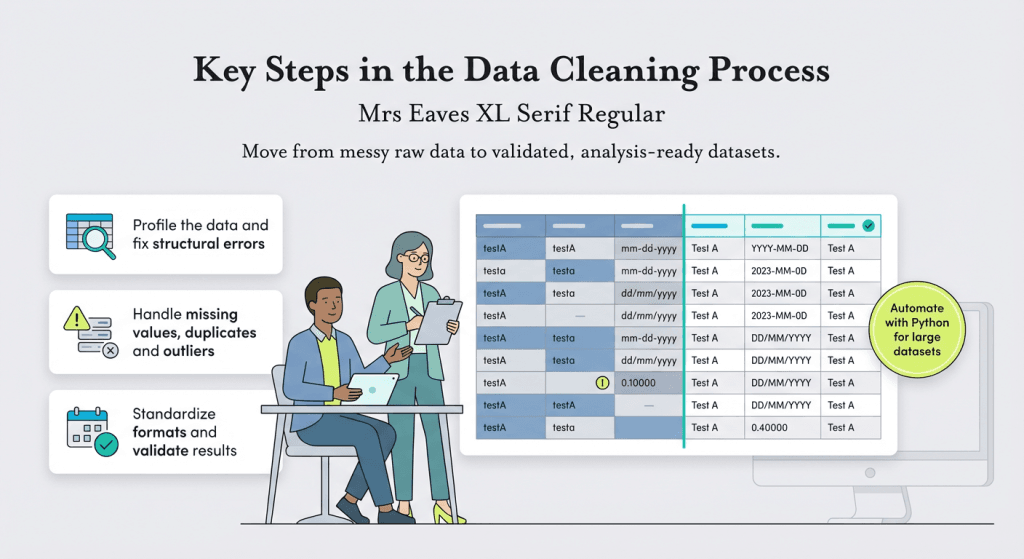
“First, you need to understand what you’re dealing with — profile the data, see what’s broken or missing, note any outliers and identify patterns in the messiness,” Papalian said. “If there are outliers, you need to take a step back to make sure you have the full context the data set is communicating. Then you tackle structural issues like fixing data types and standardizing formats.”
Once the structural issues have been resolved, it’s time to address missing data, Papalian explained, by either filling it in, removing it or flagging it. Then data should be deduplicated and checked for consistency.
While the key steps of data cleaning vary, businesses and analysts should keep the following items in mind.
- Spell checking. Make sure there are no typos in the dataset that could affect later analysis.
- Trailing spaces. Ensure that data fields do not include trailing spaces for numbers or strings. This could introduce analytical differences in the dataset.
- Fix structural errors. Ensure that values are standardized, such as choices for capitalization, naming conventions and labeling. Differences within standardization choices, such as not standardizing capitalization between “testA” and “testa,” leads to the introduction of variables and analytical errors down the line.
- Identifying and correcting missing values. Missing data can prevent analysis. For missing data, either drop missing values, guess the missing value based on other data and statistical tools, or use default records as a stand-in.
- Converting and standardizing units. Ensure all relevant data uses the same units.
- Deduplicating rows. Duplicate records can throw off statistical results; be sure to delete them prior to analysis.
- Standardizing dates. Ensure all dates in the data follow the same format. This is particularly important if pulling the data from multiple countries, where date formats may differ.
- Watch for outliers. On a case-by-case basis, remove outliers. Sometimes they can be deceptive and due to a mistake in data collection and should be removed. In other cases, outliers can offer useful information in analysis.
“You can also automate a lot of the data cleaning process using Python [the programming language], which will save you time and reduce error, especially with those larger datasets,” Ginder said. “Python can be a powerful tool for automating everyday tasks. Even if you’re just using spreadsheets now, it’s worth looking into to see if it could help enhance your workflow.”
[Interested in learning Python? Take a look at free tools to learn coding basics].
Regardless of the prior steps taken, the final step in data cleaning is always data validation, Papalian said. Take a look at your now clean dataset and ask yourself if everything makes sense. If there are outliers, are they significant and there on purpose and not due to mistakes? Are there any data quality issues present? Is each row and column of data consistent in format, unit and quality?
“The biggest mistake is jumping straight to fixing problems without understanding the full scope first,” Papalian said. “You need that discovery phase or you’ll miss critical issues.”
Once the data appears clean, tidy and standardized, you are then ready to move onto using the data for analysis.
Data tidying is a helpful component of data cleaning. This focuses on making the dataset easier to visualize, manipulate and model by introducing specific guidance for useful data structures.
How does data cleaning differ from data minimization?
Overall, data minimization and data cleaning are both crucial for any business’ overall data strategy. However, data cleaning is only relevant while the data is about to be used. Data minimization, on the other hand, is about how to collect and store the data while it is not being analyzed.
While data cleaning is about preparing data for analysis, data minimization is focused on the proper, intentional and responsible acquisition and retention of high-quality data. The core themes of data minimization are a focus on only keeping necessary data for an operation, using the data solely for its intended purpose and restricting data access to only those with a need to know.
Data minimization is a core tenant of robust data management. Its focus on deleting and de-identifying data once it has met its stated purpose for collection make it an essential component of data protection, governance and data hygiene regimes.
Overall, data minimization helps protect businesses from regulatory fines and limits the impact of data breaches by ensuring organizations only have the information they need at the moment. This focus on quality data also makes organizations more efficient by reducing out-of-date data employees may need to sift through to retrieve the most current data.
Ultimately, Papalian said, data cleaning, transformation and minimization “work together, but the goals are different. You typically clean first, then transform, then minimize as needed.”
While data minimization is not technically part of the data cleaning process, effective data minimization procedures can help keep data clean. As data minimization keeps the amount of data down to just what you need, this will save you time in the long run when conducting data cleaning.
What are the main components of quality data?
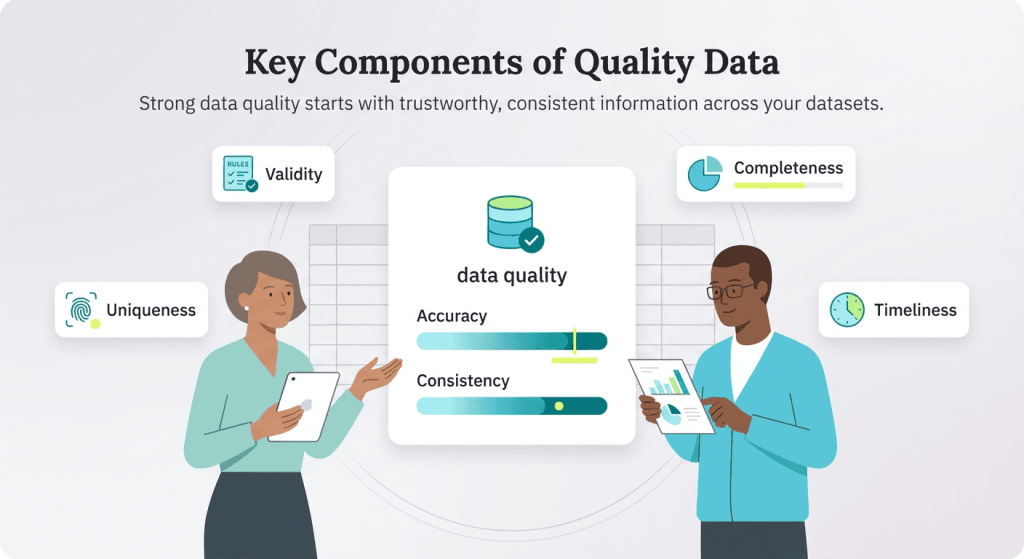
Data quality is marked by determining the data’s characteristics compared to the use cases and applications of the data for your particular use case. This means that definitions of data quality can vary slightly.
In general, the following characteristics are a good baseline of what to look for in quality data.
Accuracy
Accuracy is aimed at ensuring data is meeting the intended, true values. This should be based upon an agreed upon “source of truth,” as multiple sources may all be reporting on the same metric. To ensure clean data, data values should be based on the source of truth while additional sources of data should be used to confirm confidence in the primary source.
Completeness
Completeness refers to the percentage of data that is usable or complete within a dataset. The more complete a dataset is, the better. Low completeness, meaning an abundance of missing values, can lead to incomplete analysis or bias.
Consistency
Consistency is a measure of how consistent data is within and across datasets. Like with accuracy, consistency can be checked by using multiple datasets to ensure consistent trends within data. Within a single data set, consistency measures certain data fields against each other. For example, consistency would ensure that a single client’s order totals are less than the total order numbers across all clients.
Timeliness
Timeliness measures the readiness of data within a set time period and if it is current enough for the existing use case. Typically, timeliness measures if data can be generated in real-time.
Uniqueness
Uniqueness refers to ensuring that there are no duplicate records in the data.
Validity
Validity refers to ensuring all data meets business expectations, rules for the task and expected formats. For example, validity would ensure that the data meets a prescribed date range and includes the needed metadata. “For most analysts, it’s best to start by focusing on accuracy and consistency,” Ginder advised. “If the data isn’t correct or it’s all over the place, any insights drawn from it will be misleading. You don’t need perfect data, but you do need trustworthy data.”
What are the benefits of data cleaning?
Successfully cleaning data leads to a marked increase in the overall quality of data. As mentioned, this can prevent losses associated with poor data and garbage output. But aside from just preventing companies from losing money, data cleaning can also provide a series of marked, associated benefits.
Benefits will vary based upon company, use cases for data, workflows and more. However, some of the most basic benefits that data cleaning provides include:
- Produce better insights. Clean data leads to better quality analysis. This can help businesses generate insights that are much more likely to be true, whether you are analyzing market conditions, customer sentiment or anything else.
- Improve decision making. With better insights into the market and customers, businesses can produce and support their business intelligence operations. This helps leaders make more informed decisions.
- Reduce costs and improve compliance. Cleaning data can help businesses identify inaccurate or outdated data. This effort then is rolled into data minimization by deleting data that is no longer necessary, reducing data storage costs and bringing organizations into compliance.
- Increase efficiency. Cleaning data takes time and upkeep. But a clean database helps other employees quickly grab and use relevant data that they can be sure is up-to-date and of good quality.
- Better customer experience. Ultimately, this allows customers to have a better customer experience as businesses can more accurately tailor their offerings to meet client needs.
Overall, Papalian said the main return on investment from data cleaning is most significant across three areas: improved decision quality, increased operational efficiency and risk reduction. However, “the compound effect is what really matters,” she said. “Clean data enables better analysis, which leads to better decisions, which drives better outcomes across the organization.”